
Willkommen bei der Dokumentation von CareLit Complete. In dieser Anleitung erklären wir Einrichtung, Funktionsweise und Best Practices des Link‑Resolvers.
Der Link‑Resolver erzeugt aus bibliographischen Metadaten zielgenaue Links zu externen Diensten wie SFX/Alma, Clarivate 360Link, DOI, EZB, DOAJ, Verlags‑Homepages oder einen Mail‑Resolver. Die Auswahl des passenden Ziels erfolgt regelbasiert anhand konfigurierbarer Bedingungen (JSON) sowie einer Priorität pro Resolver.
UI-Einstieg: Hilfe → Link‑Resolver

Über Neu anlegen legen Sie einen Resolver an. Existierende Resolver lassen sich direkt in der Tabelle bearbeiten, testen, deaktivieren/aktivieren oder löschen.
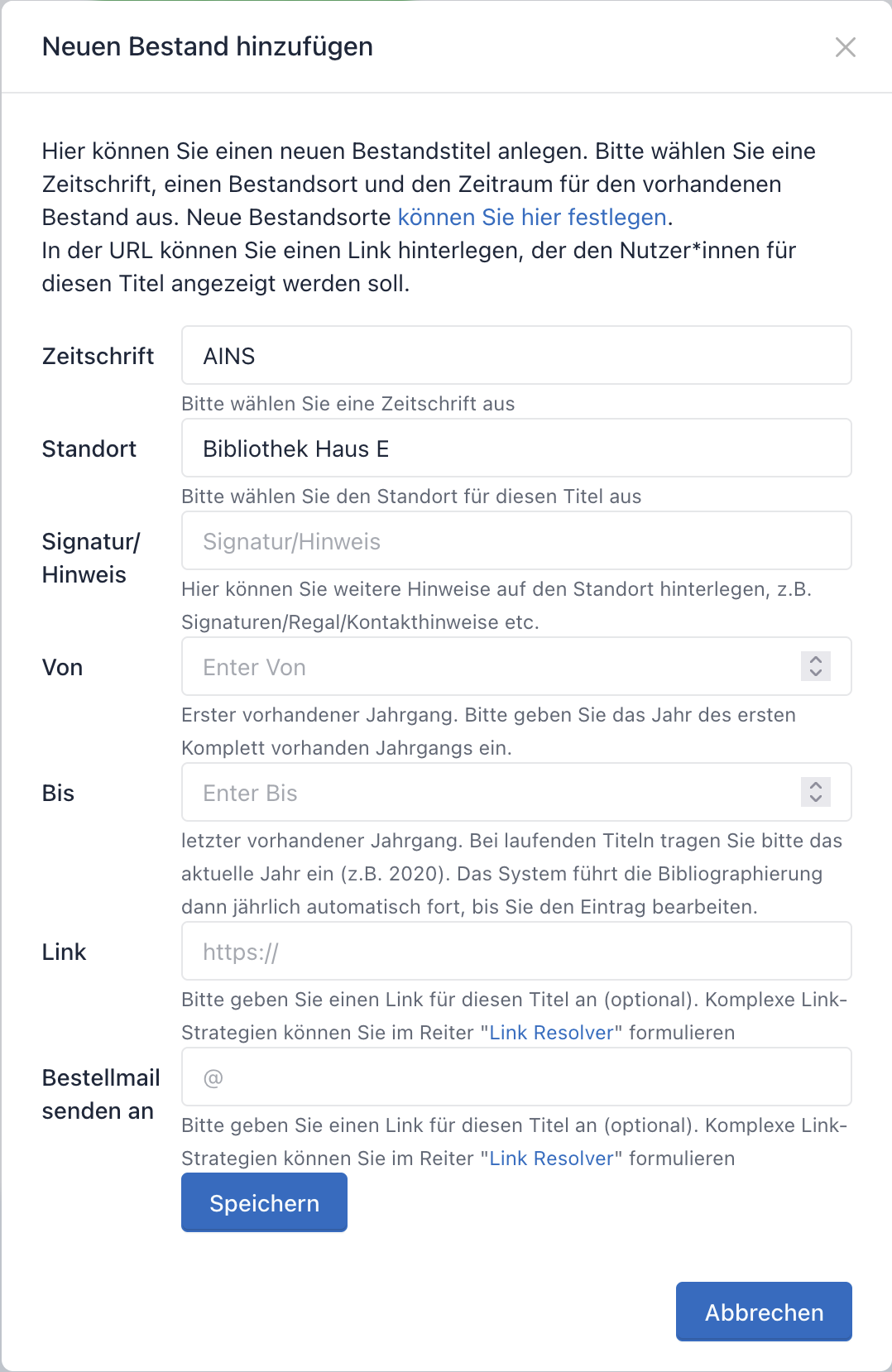
Über die Buttons unter Vorlagen übernehmen Sie geprüfte Templates – Hostnamen bitte an Ihre Umgebung anpassen.
ZEITSCHRIFTEN.WEBADRESSE.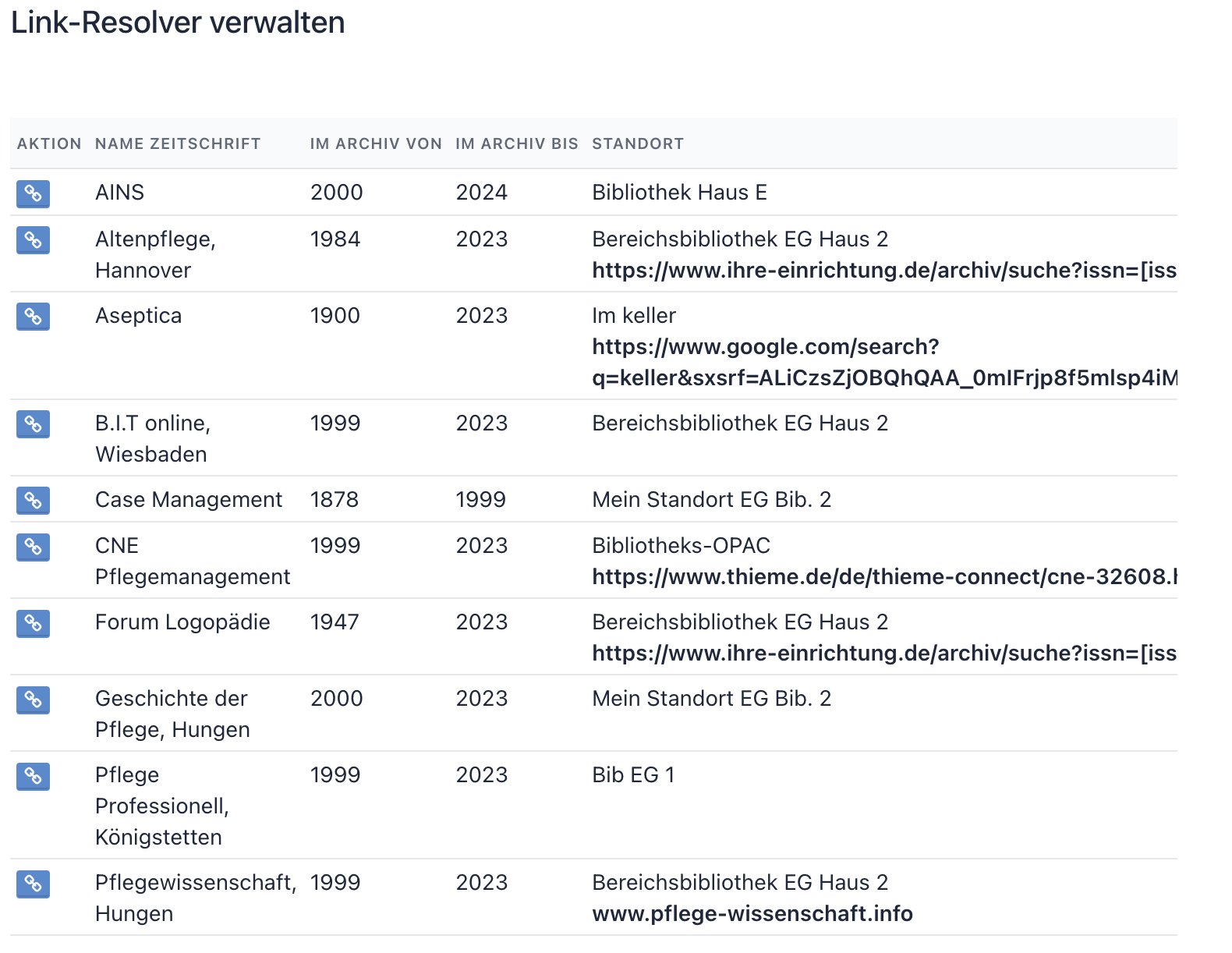
Die Bedingungen werden serverseitig mit JSON-Vorlagen geprüft (UND‑Verknüpfung aller Felder). Erlaubt sind:
"FELD":"Wert" – exakter Vergleich (als String)."FELD":{"contains":"…"} – Teilstring (case‑insensitive)."FELD":{"in":["A","B"]} – Wert ist in Menge."FELD":{"regex":"/…/i"} – regulärer Ausdruck (PCRE).Beispiele
{"ISSN":"1439-1074"}
{"DOI":{"regex":"/^10\\./"}}
{"ZEITSCHRIFT":{"contains":"Pflege"}}
Die Felder können sowohl aus dem Dokumen-Metadatenset (METADATEN) als auch aus der Zeitschrift (ZEITSCHRIFTEN-METADATEN) kommen – u. a. ISSN, ZEITSCHRIFT, DOI, JAHRGANG, HEFT, SEITE, ZS_HOMEPAGE uvm.
Im Template ersetzen wir Platzhalter aus Dokument und Zeitschrift. Die Variante {FELD:url} URL‑kodiert den Wert.
{DOKUMENT_nr}, {AUTOR}, {TITEL}, {ZEITSCHRIFT}, {ZS_ID}, {ISSN}, {JAHRGANG}, {HEFT}, {SEITE}, {DOI}, {Jahr}, {Monat}, {ISBN}, {ZS_HOMEPAGE}, {ZS_VERLAG}Beispiel OpenURL
https://sfx.MEIN-BIB-HOST/openurl?url_ver=Z39.88-2004&sid=carelit&rft.genre=article&rft.issn={ISSN:url}&rft.jtitle={ZEITSCHRIFT:url}&rft.atitle={TITEL:url}&rft.date={Jahr:url}&rft.volume={JAHRGANG:url}&rft.issue={HEFT:url}&rft.spage={SEITE:url}&rft_id=info:doi/{DOI:url}
Mit dem blauen Test‑Button in der Tabelle wird der Resolver gegen eine CARELIT-DOKUMENT-ID geprüft. Der Server iteriert in Prioritätsreihenfolge und verwendet den ersten passenden Resolver. Falls keiner passt, greifen Fallbacks:
https://doi.org/{DOI}{ZS_HOMEPAGE}
Die ausgewählten Resolver erscheinen als Buttons neben dem Treffer. Beschriftung und Popover‑Hinweise stammen aus den Feldern Bemerkung / Notizen.

Google Scholar
https://scholar.google.de/scholar?hl=de&as_sdt=0%2C5&q={TITEL:url}
EZB (Regensburg)
https://ezb.uni-regensburg.de/vascoda/openURL.phtml?sid=CARELIT:ALL&genre=article&issn={ISSN:url}&date={Jahr:url}&volume={JAHRGANG:url}&issue={HEFT:url}&spage={SEITE:url}&author={AUTOR:url}&atitle={TITEL:url}
Ovid LinkSolver
http://linksolver.ovid.com/OpenUrl/LinkSolver?genre=article&issn={ISSN:url}&isbn={ISBN:url}&title={ZEITSCHRIFT:url}
MEIN-BIB-HOST, MEIN-360LINK-Host, EZPROXY-HOST)./^\d{4}-\d{3}[\dxX]$/ als Bedingung möglich.{FELD:url} für korrekt codierte Parameter.contains/Regex einsetzen.Sie können beliebig viele Link‑Resolver definieren. Achten Sie auf eindeutige Prioritäten, um die Prüf‑Reihenfolge transparent zu halten.
Ein Link‑Resolver prüft, ob und wo eine Bibliothek Zugriff auf einen Artikel bietet. Aus Metadaten (Titel, ISSN, DOI, Jahrgang, Heft, Seite …) wird eine OpenURL oder eine Zieldomain gebildet. Die Nutzer:innen werden dann zur passenden Ressource ihrer Institution geleitet (z. B. SFX/Alma, 360Link, Verlagsseiten, Proxy‑Zugänge).
Link‑Resolver arbeiten oft mit Discovery‑Services zusammen, um E‑Ressourcen benutzbar zu machen. In CareLit definieren Sie die Regeln selbst – granular, transparent und jederzeit änderbar.